
The Stochastic CPU

The Agentic AI Architect: Week 1
Why LLMs are just a new type of processor, and how to benchmark them.
Last week, I wrote about The Agentic Data Engineer, and the response was overwhelming. 40,000 impressions and hundreds of new connections later, one thing is abundantly clear: Data Engineers are ready to evolve.
We are tired of being “plumbers.” We want to be architects.
So, I’m doubling down. I am turning that single blog post into an open-source, 8-week curriculum called The Agentic AI Architect. I’m building it in public, and you can follow along.
I have renamed and restructured the repo to support this journey.

Star the Repo: github.com/snudurupati/agentic-ai-architect
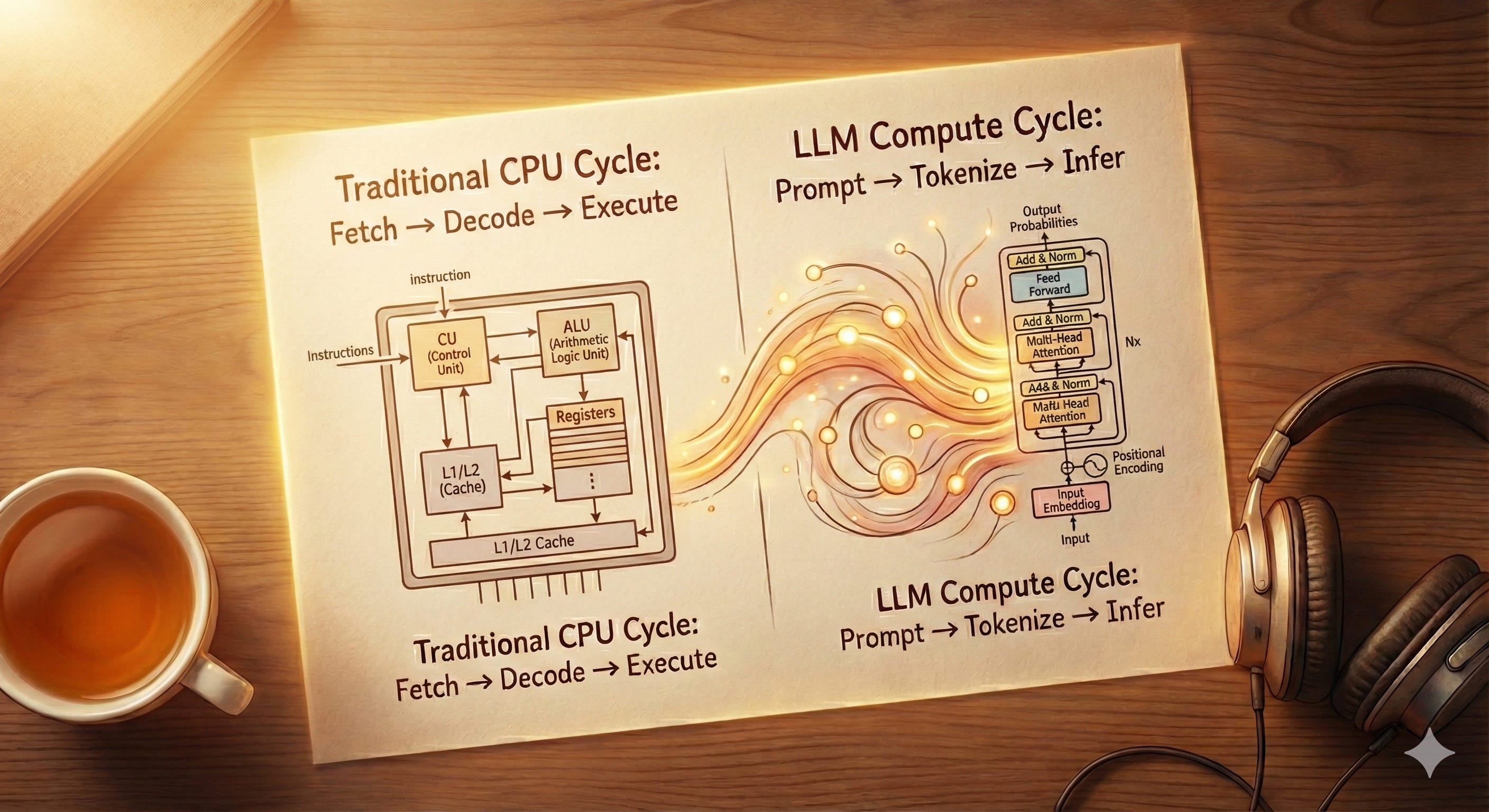
We start today with Week 1: The Stochastic CPU.
The Mindset Shift: It’s Not Magic, It’s Compute
The biggest mistake I see developers make is treating LLMs like magic genies. You rub the lamp (send a prompt), and you get a wish (an answer).
To build production systems, you need to stop thinking of them as magic and start treating them as a Stochastic (Probabilistic) CPU.
Your Laptop CPU: Deterministic. 2+2 always equals 4.
The LLM CPU: Probabilistic. 2+2 is probably 4, but depending on the temperature, it might be “Four” or “Math is a social construct.”
As an architect, your job isn’t to marvel at the intelligence; it’s to manage the constraints of this new processor.
1. Context Window is the New RAM (And it has Amnesia)
If an LLM is a CPU, the Context Window is its RAM. But unlike your laptop, this RAM gets wiped clean after every single operation.
The “Hidden” Cost of Chat:
When you use ChatGPT, it feels like the model remembers you. It doesn’t. The application secretly copies your entire conversation history and pastes it back into the prompt for every new message. This means every time you ask a follow-up question, you aren’t just sending 5 words; you are re-sending the previous 5,000 words.
Why “Quadratic Scaling” Matters (The Data Engineer Analogy):
You might hear that Attention scales “quadratically.” What does that actually mean?
Think of it like a SQL Join. When an LLM processes text, it doesn’t just read linearly. It compares every token to every other token to understand the relationships (Attention).
In SQL terms: It is a Self-Cross Join (Cartesian Product) of the input data.
Input: 10 tokens → Join checks 100 relationships.
Input: 100 tokens → Join checks 10,000 relationships.
Input: 100k tokens → Join checks 10,000,000,000 relationships.
This is why a 128k context window isn’t just “more storage”, it’s an exponentially harder math problem that slows everything down.
Cloud (128k) vs. Local (32k):
Cloud (GPT-4o): With a 128k window, you can “Join” an entire book or a massive codebase in one go. The cloud provider has the massive H100 clusters required to handle that explosion of compute.
Local (Ollama/GPT-OSS:20B): If your local model has a 32k limit, that is your hard RAM ceiling. If you try to feed it a 50-page document, it’s like trying to load a 1TB CSV into a 16GB laptop. It will either crash (OOM) or you will have to truncate (delete) data, causing the model to “forget” the beginning of the document.
The Data Pipeline of Thought: From Words to Vectors
Before we write code, we need to understand the data pipeline. You are used to ETL (Extract, Transform, Load). LLMs have their own pipeline: Tokenize, Embed, Infer.
Step 1: Words → Tokens
LLMs do not read “English.” They read numbers. The Tokenizer is a pre-processor that chops text into chunks.
Text to Token (The Chop): The tokenizer splits text into chunks.
Input: “Applesauce”
Tokens:
"Apple"and"sauce"(Two distinct chunks).
Token to ID (The Lookup): The system looks up these chunks in its fixed vocabulary dictionary.
"Apple"→ID 452"sauce"→ID 8812
ID to Embedding (The Meaning): The GPU looks up
ID 452in its learned memory and retrieves a vector.ID 452→[0.02, -0.44, 0.91, ...]
Why this matters: We don’t pay API providers for words; we pay for those integer chunks (IDs). And the conversion from ID to Vector? That is the model’s “brain” that it learned during training.
The “Vocabulary” Hook:
Every model comes with a fixed Vocabulary, a specific list of words it knows. If you swap the tokenizer (e.g., use Llama’s tokenizer with GPT-4’s model), the model will receive the wrong IDs. It’s like sending a French dictionary code to an English speaker.
Architect’s Note: This
Token -> Embeddingtranslation is learned during training. It is the foundation of the model’s intelligence. This will become critical in Week 3 (RAG), because if you use an embedding model that speaks a different “vector language” than your LLM, your search results will be garbage.
Conclusion: The Architect’s Trade-Off
As an architect, you don’t pick the “best” model. You choose the right one for the Constraint.
Here is how you decide:
The Context Constraint: Do you need to paste a 50-page PDF into the prompt?
Yes: You need Cloud (GPT-4o, Claude 3.7). Most local servers (Ollama) default to 8k or 32k context windows to prevent your RAM from exploding.
No: If you are just summarizing emails, Local is fine.
The Latency Constraint:
Cloud: Generally consistent (~1-2s).
Local: Depends entirely on your hardware. On an M4 Mac, a small model (Llama 3.2 3B) is lightning fast (<0.5s). A large model (GPT-OSS:20B) might take 30 seconds per reply. If your app requires sub-second responses, stick to small local models or optimized cloud endpoints.
The “Classic ML” Reality Check: Before you spin up a GPU cluster, ask yourself: Do I actually need Generative AI?
If you are classifying transactions as “Fraud” or “Not Fraud,” and you have 100,000 labeled examples, do not use an LLM. Use XGBoost or Logistic Regression.
Classic ML is reproducible, 1000x cheaper, and 1000x faster. Utilize LLMs for reasoning and handling ambiguity, rather than for simple pattern matching.
The Build: llm_benchmark.py
“An ounce of action is worth a ton of theory.”
For Week 1, we aren’t building a chatbot. We are building a Latency & Cost Profiler. If you are going to put AI in production, you need to know exactly how much “thought” costs.
I wrote a script that races OpenAI (GPT-4o) against a local model (GPT-OSS:20B) running on my M4 MacBook Air with 24GB RAM. The results were surprising.
Link to Code: Week 1 – The Stochastic CPU
The Findings (M4, 24GB RAM):
Cloud (GPT-4o-mini): 1.6s latency. (Fast, but costs money).
Local (GPT-OSS:20B): 15.7s latency. (Free, but slow).
The Takeaway:
My local machine struggled with the 20B model (15s is too slow for a chatbot). To make local viable on this hardware, I would need to scale down to a smaller model (like Llama 3.2 3B) or accept the cost of the Cloud.
The Architect’s Quiz (Homework)
I’m digging deep into the internals of why these models work the way they do. If you really want to master this stack, try to answer these five questions before next week.
Tip: Don’t just guess. Fire up your favorite model: ChatGPT, Gemini, or Claude and ask it to explain these concepts to you “like a Data Engineer.”
The “Pre-Processing” Step: In classic ML, we manually create features (feature engineering). LLMs have a “Tokenizer” built-in. Why can’t we just feed them raw text or use our tokenizer?
The Dictionary: Where does the model store its vocabulary?
The Billing Question: Since “compute is compute,” why do OpenAI and Anthropic charge us by the Token and not simply by the Word?
Vector Math: Does GPT use “One-Hot Encoding” to represent words, or something else?
Positioning: When you send a sentence to an LLM, does it automatically know that “Select” came before “From”? Or do we have to explicitly tell it?
What’s Coming Next?
We have defined our compute. Next, we need to write the software.
Week 2: Prompt Engineering as Code
We are ditching the “prompt poetry.” No more “Please act as a helpful assistant.” Next week, we treat prompts as Software Contracts. We will force the LLM to output structured, valid JSON, handle errors, and build a deterministic classification system.
Your Action Items:
Fork the Repo: agentic-ai-architect
Run the Benchmark: See how your machine handles local models.
Do the Research: Ask your favorite AI to explain “Positional Embeddings” and see what you find.
See you in the repo.
The Robot Brain Diaries